
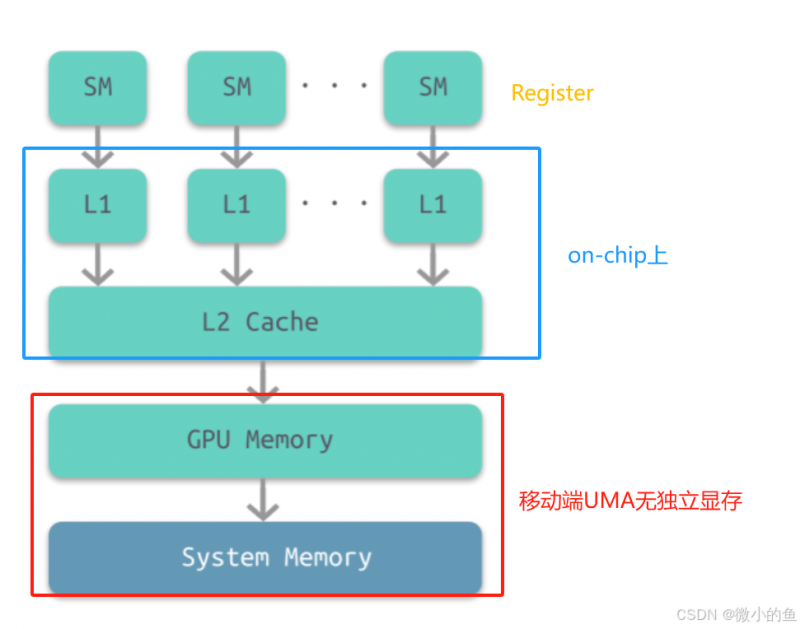
先简述移动端内存cache结构;上图的UMA结构 on-Chip memory 包括了 L1、L2 cache,非常关键的移动端的 Tiles 也是保存在 on-chip上还包括寄存器文件:提供给每个核心使用的极高速存储。
- 共享内存(Shared Memory):用于同一计算单元内的线程组SM共享数据,访问速度比全局内存快。
- 常量缓存(Constant Cache):专门用于缓存常量数据。
- 纹理内存(Texture Memory):类似于常量缓存,也是具有缓存的全局内存,容量较大且一般仅可读。它们通过特定的方式进行访问,适用于纹理采样等操作。
下图以arm 的mail为例(以后有机后再展开说):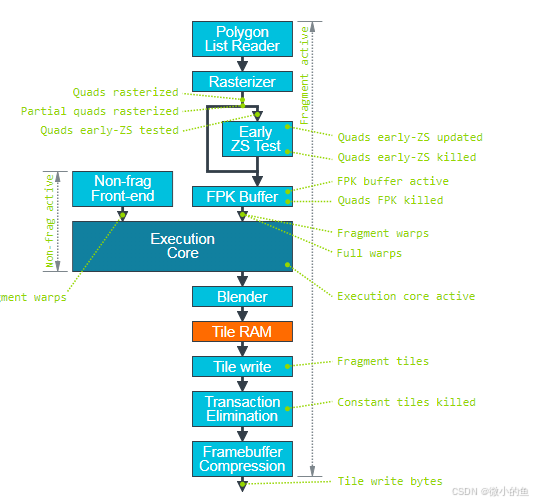
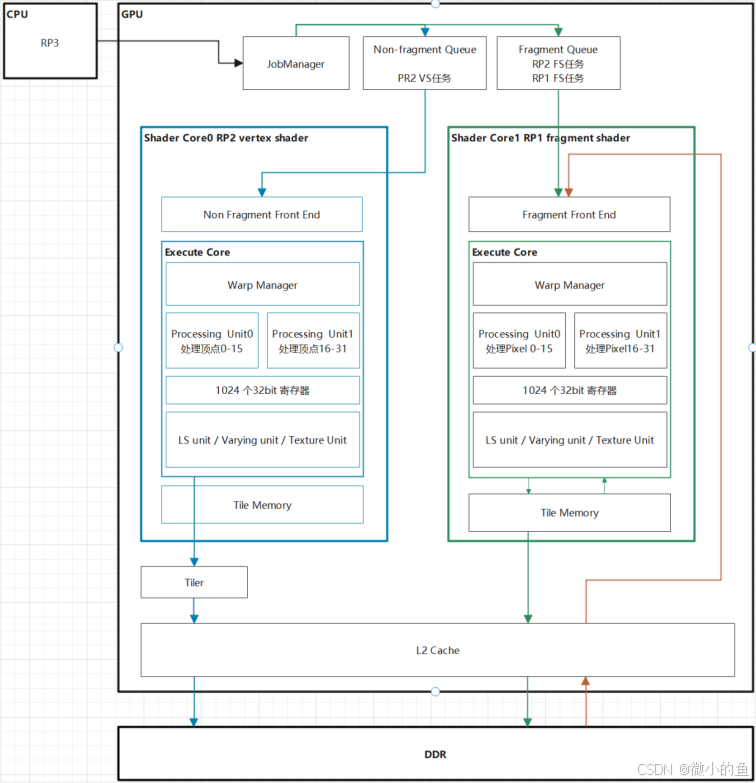
- load与 store决定了每个Render Pass开始时如何处理Tile内存中的数据。
- 从 SystemMemory 拷贝数据到 TileMemory 是 Load Action。
- 从 TileMemory 拷贝数据到 SystemMemory 是 Store Action。
在移动端图形中GPU Load Actions(加载操作)决定了在渲染一个新的帧缓冲区FBO,如何处理FBO中已经存在的数据,这在优化性能和内存带宽方面非常重要。主要有三种GPU Load Actions:don‘t care、Load、Clear。

在移动端图形中GPU Store Actions(存储操作)决定了在渲染完成一帧后如何处理FBO中已经存在的数据:主要有三种dont’care 、resolve、store


Apple 的Store Action 有三种, Store, DontCare,MultisampleResolve ,还有两种处理 MSAA 等的 metal、vulkan 的storeAndMultisampleResolve, MultisampleResolve. 感兴趣可以直接参苹果的文档 metal Best Practices Guide: Load and Store Actions
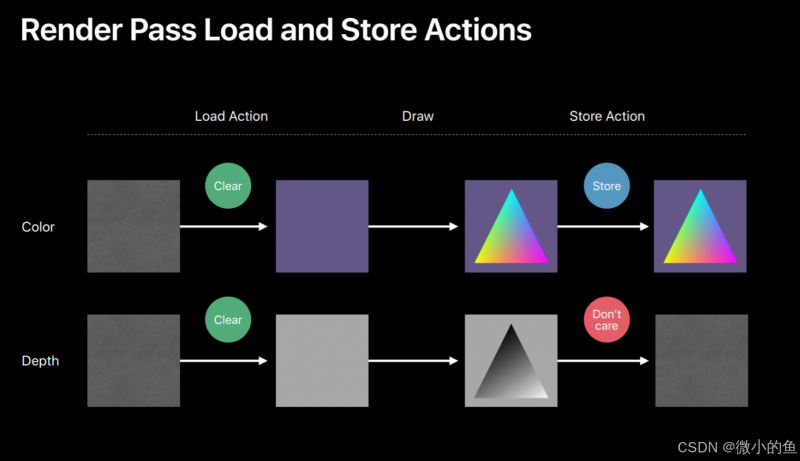
想要优化pipline的性能,就一定要注意设置好每个RenderTarget的Load Action 和 Store Actions。比如,Depth和Stencil通常只有在Rasterize阶段才会使用,所以直接放到了On-chip上, 或者后处理执行后深度没有用Store Actions设置为Don‘t care这样就不用把结果写入system内存,省下了大量的带宽。
Fast Clear 是 GPU 对帧缓冲区进行快速clear的一种硬件优化机制。当帧缓冲区被clear时,只需将每个像素初始化到一个特定的颜色值。如果直接操作整个帧缓冲区对整个缓冲区的逐步遍历,会非常耗时
Fast Clear 本质上是一些硬件预设的清除值,比如clear成黑色或者白色这种,比自己传一个clear value进去要快!现代的硬件都有 Fast Clear,不管是 PC 、Apple A系列、Adreno等都支持。
调用 clear 的时候根据硬件支持与驱动的设置会触发Fast Clear。比如在 amd 上Fast clear 在设计上比不同clear快约100倍(压缩了省带宽所以快了100倍)
- Fast clear 需要全图像clear。
- Fast clear RT的 需要以下颜色RGBA(0,0,0,0),RGBA(0,0,0,1),RGBA(1,1,1,0) ,RGBA(1,1,1,1)
- Depth RT Fast clear 需要将深度值设为1.f或者0.f。
- 模板设置值为 0x00。
- Depth target arrays 需要将全部slices都清除才能实现fast clear。
- vulkan 与 D12有Discard或LOAD_OP_DONT_CARE 标记时(opengles 无),会跳过Clear。
transaction elimination 技术
这里特别澄清之前一个错误,ARM使用的Transaction Elimination 的技术与fast clear没有关系! transaction elimination是一种很有效的降低带宽的方法。在有些场景下,只有部分Tile中的内容会变化(例如摄像机不动,一个Tile中只有静态物体)。此时通过比较该Tile前一次和本次的渲染结果的 循环冗余校验(CRC值),可得到Tile是否变化的结论,如果不变,那么就没有必要执行Tile到System Memory的store写回操作了,有效地降低了带宽占用。并仅对其中已修改的特定部分执行部分更新,能显著减少每帧需要传输到外部内存的数据量。TE 可以被每个应用程序用于 GPU 支持的所有帧缓冲区格式,而不管帧缓冲区精度要求如何,并且非常有效,即使在第一人称射击 (FPS) 游戏和视频中也是如此。在大部分frame buffer在两个连续帧之间保持静态,TE 的帧缓冲带宽节省高达 99%。
在 opengl 中don’t care 对应的是glinvalidate,clear对应glclear,综上所述在 opengl 中glinvalidate与glclear不等价。所以glinvalidate应该会比clear会更好。glInvalidateframebuffer 在 ogles2.0 是需要扩展,在 es3.0 是支持的详细参考 gl 文档: glInvalidateframebuffer - OpenGL ES 3 Reference Pages
pipline开始时将显卡内存初始化使用glclear然后fast clear设置为特定颜色值,而无需system从内存中读回旧的帧缓冲区内容。在进行任何绘制调用之前,除非需要前一帧中渲染的内容上做处理,都可以使用以下的
你需要使用 glclear 、glClearBuffer、glInvalidateframebuffer给 GPU 驱动标记opengl驱动会自己优化load过程。但是需要特别注意:每一帧中只有开始是免费(几乎无消耗)的。在pipline中的第一次绘制调用再后调用 glClear() 或 glClearBuffer*() 不是免费的,会增多指令并且这会导致每个着色器的片段都会被清除。同时这些是清除整个 framebuffer,而不仅仅是它的一个子区域!
对于store过程,最重要的是可以通过调用glInvalidateframebuffer()作为pipline中的最后一个绘制调用,将内容标记为无效!
arm Mali参考
Minimizing-Start-of-Tile-Loads
Minimizing End of Tile Stores
gl 的例子 glInvalidateframebuffer(GL_frameBUFFER, 1, &attachment);
首先,特别注意:
1、issues在 GPU 中是专业术语不能直接翻译成“问题”应该翻译成“发射”或者”调度“用于描述GPU在某个时钟周期内,某种操作(例如读、写、计算)被硬件单元执行或发射的次数。
2、beats 指的是内存控制器中的一个传输单元。它代表一次数据传输中的“拍子”或“节奏”,可以理解为传输过程中一个周期内的数据量。因此,这里的 beats 应该翻译为“传输单位”。
其次,如下表的指标主要是android GPU inspector的指标也是最全的,同样的 Arm 、adreno 等的指标都是下表的特定指标;

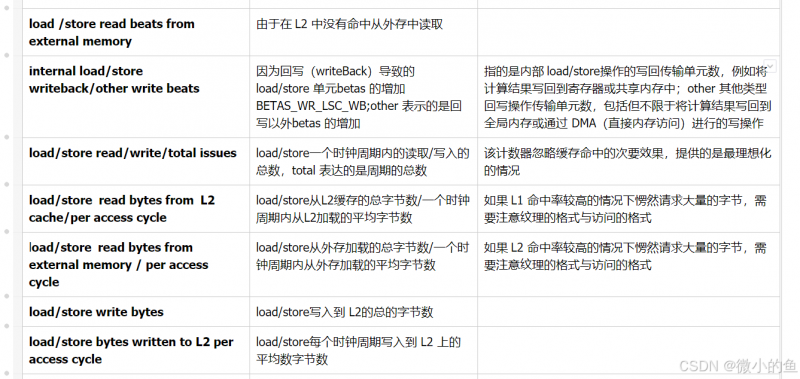

Demo假设你在分析一个 GPU 程序,并且性能分析工具streamline提供了如下参数值:
Load/Store Read Beats from L2 Cache: 5000
Load/Store Read Beats from External Memory: 20000
Internal Load/Store Writeback/Other Write Beats: 15000
从这些数据你可以推断出:
- 程序高度依赖外部内存:因为从外部内存的读取节拍(20000)显著高于从 L2 缓存的读取节拍(5000),表明许多数据访问没有命中 L2 缓存。
- 写操作较频繁:内部加载/存储写回和其他写操作节拍总数(15000)表明有大量的数据写入,可能是计算结果或状态更新(这个时候使用dontcare会有较好的优化效果)。
假设你有以下参数值:
- Load Read Bytes from L2 Cache:320000 / 每访问周期 64 字节
- Load Read Bytes from External Memory:640000 / 每访问周期 128 字节
从这组数据中可以看到: - 从 L2 缓存读取总共 320,000 字节,平均每个访问周期读取 64 字节。
- 从外部内存读取总共 640,000 字节,平均每个访问周期读取 128 字节。
尽管外部内存每个周期读取的字节数较大,但外部内存访问的延迟比 L2 缓存高,整体访问效率可能较低。因此,如果程序频繁地访问外部内存,而不是 L2 缓存,可能会导致性能下降。在这种情况下,优化策略可能包括:
- 提高 L2 缓存命中率,通过更有效的数据布局(内存对齐)和访问模式减少对外部内存的依赖。
- 使用共享内存(内存数组等)或寄存器来缓存频繁访问的数据,从而减少全局内存访问。