

一、ICMP协议

首先需要了解一下ICMP协议,即:网络控制消息协议(Internet Control Message Protocol)。
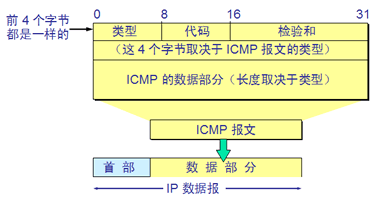
ICMP是TCP/IP协议族的一个子协议,工作在网络互联层(网络层)。ICMP协议是一种面向无连接的协议,用于传输出错报告控制信息。用于在IP主机、路由器之间传递控制消息。控制消息是指网络通不通、主机是否可达、路由是否可用等网络本身的消息。这些控制消息虽然并不传输用户数据,但是对于用户数据的传递起着重要的作用。
二、地址解析协议ARP
我们经常会遇到这样的问题,已经知道了一个主机的IP地址,需要找到其对应的物理地址。因为将IP数据报封装到MAC帧里面的时候需要知道目的地址的MAC地址。地址解析协议ARP的作用就是根据主机的IP地址来获得物理地址。
每个主机都设有一个ARP高速缓存(ARP cache),这里面放着的是主机已经知道的IP地址和MAC地址的映射表,并且这个映射表还是经常动态更新的。
1)ARP的工作原理
当主机A想要同本局域网上的某个主机B发送IP数据报时,就先在其ARP高速缓存中查看有无主机B的IP地址。如果有,就在ARP高速缓存中查找器对于的硬件地址,再把这个硬件地址写入MAC帧里,然后通过局域网把MAC帧发往此硬件地址。也有可能在ARP高速缓存中查不到主机B的IP地址(主机A缓存为空,或主机B刚加入局域网),这样也就无法知道主机B的MAC地址,这时候就需要使用到ARP了,按以下步骤来获得主机B的硬件地址。
①主机A的ARP进程在本局域网上广播发送一个ARP请求分组,以广播的形式,格式如图a所示。
②在本局域网上的所有主机上运行的ARP进程都受到了这个ARP请求分组。
③主机B在ARP请求分组中发现了自己的IP地址,就向A主机发送ARP响应分组,以单播的形式直接发给A,以如图b所示。同时主机B知道了A的IP地址和MAC地址,就将主机A的IP地址和MAC地址写入ARP高速缓存中。其他主机在对比IP地址之后,发现与自己的IP地址不同,就丢掉分组。
④主机A收到主机B的ARP响应分组之后,这样就知道了主机B的MAC地址,同时把主机B的IP地址和MAC地址写入ARP高速缓存。
上面所描述的情况是在同一局域网下的情景,如果主机A要同不在同一局域网下的主机B进行通信,发送IP数据报。首先主机A将主机B的IP地址同自己的子网掩码进行比对,发现不在同一局域网内,则利用ARP请求分组,根本局域网上的路由器的IP地址来获取路由器的MAC地址,然后将剩下的工作交给路由器去做即可。
2)ARP的四种典型情况
①发送方是主机,要把IP数据报发送到本网络上的另一个主机。这时利用ARP找到目的主机的硬件地址。
②发送方是主机,要把IP数据报发送到另一个网络上的一个主机。这时利用ARP找到本网速上的一个路由器的硬件地址,然后把剩下的工作交给路由器去完成。
③发送方是路由器,要把IP数据报发送到另一个网络上的一个主机。这时利用ARP找到本网络上的另一个路由器的硬件地址,然后把剩下的工作交个这个路由器去完成。
④发送方是路由器,要把IP数据报发送到本网络上的一个主机。这时利用ARP找到目的主机的硬件地址。
三、ping某个域名的整个过程
ICMP的一个重要应用就是分组网间探测PING(Packe InterNet Groper),用来测试主机之间的连通性。PING使用了ICMP回送请求与回送回答报文。PING是应用层直接使用网络层ICMP的一个例子,没有经过传输层的TCP或UDP。
ping某个域名相对于ping IP地址来说,多了一些步骤,主要用来获取域名对应的IP地址,整个过程如下:
1、主机查找本地系统Hosts文件的DNS缓存,如果存在该域名对应的IP,则获取IP,跳转到第8步;如果不存在,则继续。
2、主机向本网络路由器发起请求,查找路由DNS缓存,如果存在该域名对于的IP,则获取IP,跳转到第8步;如果不存在,则继续。
3、路由器向本地ISP(互联网提供商)的DNS服务器发起请求,查找DNS服务器的缓存,如果存在该域名对应的IP,则跳转到第7步;如果不存在,则继续。
4、本地DNS服务器向根域名服务器发起请求,根域名服务器告诉本地服务器,下一次应查询的顶级域名服务器dns.com的IP地址。
5、本地域名服务器向顶级域名服务器dns.com进行查询,顶级域名服务器dns.com告诉本地域名服务器,下一步应查询的权限服务器dns.abc.com的IP地址。
6、本地域名服务器向权限域名服务器dns.abc.com进行查询,权限域名服务器dns.abc.com告诉本地域名服务器,所查询的主机的IP地址。
7、本地域名服务器最后把查询结果——该域名对应的IP地址告诉给主机。
8、至此,主机知道了该域名的IP地址。

----------------------------------(以上部分主要是根据域名获取对应的IP地址,涉及DNS)-----------------------------------
9、主机通过子网掩码判断该IP地址是本网段还是跨网段,由于本网段比较简单,我们以跨网段进行讲解。
10、主机先查看本地ARP高速缓存,查看表中是否有本网络路由器(网关)的MAC地址,如果有,则获取MAC地址,跳转到第12步;如果没有,则继续。
11、主机使用ARP解析协议获取到本网段路由的MAC地址。
12、至此,主机知道本网络一个路由的MAC地址。
---------------------------------(以上部分主要是获取本网络一个路由的MAC地址,涉及ARP)-----------------------------
13、主机将ICMP报文封装成IP数据报,IP数据报的源地址为主机的IP地址,目的地址是域名对应的IP地址;
14、主机将IP数据报封装成MAC帧,MAC帧的源地址为主机的MAC地址,目的地址是路由器的MAC地址;
12、路由器接收到ICMP报文之后,发现MAC帧的目的地址是自己,IP地址是主机想要访问的IP地址,则将MAC帧的源地址改为自己的MAC地址,目的地址改为本网段另一个路由的MAC地址(也要通过ARP协议获取),转发下去...
13、直到最后一个路由根据ARP协议,找到了主机想要访问的IP地址对应的主机的MAC地址,然后将ICMP报文封装成MAC帧发送给该域名主机。
14、由于ARP协议具有相互学习性,域名主机接收到主机发送的ICMP回送请求报文之后,将向本网络路由发送ICMP回送回答报文,该路由又会转发下去...
15、当主机收到域名主机发送的ICMP回送回答报文之后,这样就表明该主机到域名主机是连通可达的。











